
Прямо сейчас я могу открыть Google Фото, набрать «пляж» и посмотреть свои фотографии с разных пляжей, которые я посетил за последнее десятилетие. Я никогда не просматривал свои фотографии и не отмечал их; вместо этого Google определяет пляжи на основе содержания самих фотографий. Эта, казалось бы, обыденная функция основана на технологии, называемой глубокими сверточными нейронными сетями, которая позволяет программному обеспечению понимать изображения сложным способом, который был невозможен с помощью предыдущих методов.
В последние годы исследователи обнаружили, что точность программного обеспечения становится все лучше и лучше, поскольку они строят более глубокие сети и накапливают большие наборы данных для их обучения. Это создало почти ненасытный аппетит к вычислительной мощности, увеличивая состояние производителей GPU, таких как Nvidia и AMD. Google несколько лет назад разработал собственный собственный чип нейронной сети , и другие компании стремятся последовать примеру Google.
Например, в Тесла компания взяла на себя ответственность за свой проект автопилота эксперта по глубокому обучению Андрея Карпати. В настоящее время автопроизводитель разрабатывает специальный чип для ускорения работы нейронной сети для будущих версий Autopilot. Или возьмите Apple: чипы A11 и A12, лежащие в основе последних iPhone, содержат «нейронный движок», ускоряющий работу нейронной сети и позволяющий лучше распознавать изображения и голоса.
Эксперты, с которыми я разговаривал в этой статье, прослеживают нынешний бум глубокого обучения в одной конкретной статье: AlexNet, по прозвищу ведущего автора Алекса Крижевского.
«На мой взгляд, 2012 год стал вехой, когда вышла эта статья AlexNet», — сказал Шон Джерриш, эксперт по машинному обучению и автор книги « Как думают умные машины» .
До 2012 года глубокие нейронные сети были чем-то вроде затона в мире машинного обучения. Но затем Крижевский и его коллеги из Университета Торонто подали заявку на конкурс по распознаванию изображений, который был значительно более точным, чем все, что было разработано ранее. Почти за одну ночь глубокие нейронные сети стали ведущей техникой распознавания изображений. Другие исследователи, использующие эту технику, вскоре продемонстрировали дальнейшие скачки в точности распознавания изображений.
В этой части мы углубимся в глубокое изучение. Я объясню, что такое нейронные сети, как они обучаются и почему им требуется так много вычислительной мощности. И затем я объясню, почему определенный тип нейронной сети — глубокие сверточные сети — так замечательно хорош в понимании изображений. И не волнуйтесь — там будет много картинок.
Простой пример с одним нейроном
Фраза «нейронная сеть» все еще может показаться немного туманной, поэтому давайте начнем с простого примера. Предположим, вы хотите, чтобы нейронная сеть решала, должен ли автомобиль двигаться на основе зеленого, желтого и красного света стоп-сигнала. Нейронная сеть может выполнить эту задачу с помощью одного нейрона.
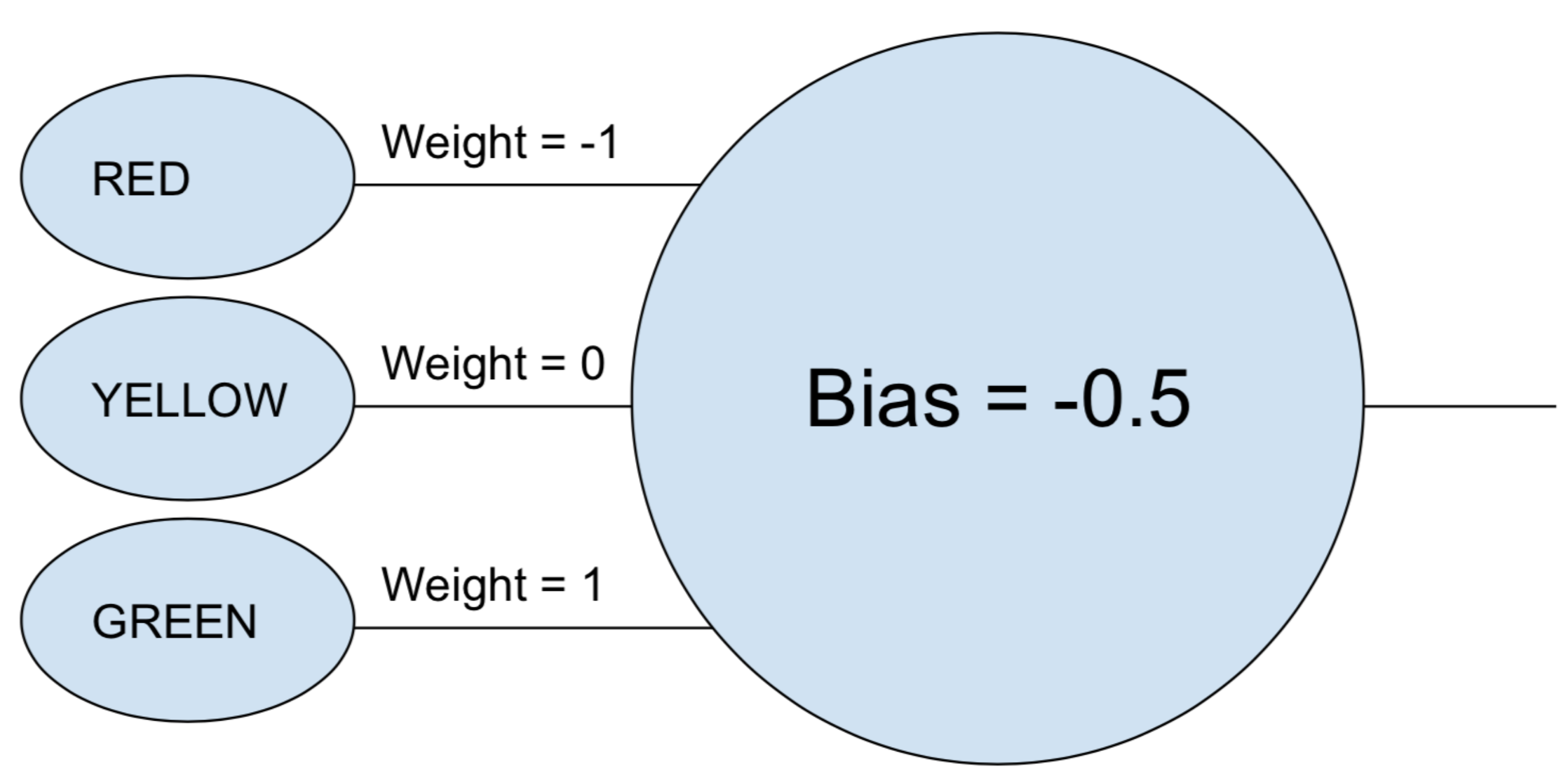
Нейрон берет каждый вход (1 для включения, 0 для выключения), умножает его на свой связанный вес и складывает все взвешенные значения вместе. Затем нейрон добавляет смещение, которое определяет порог для «активации» нейрона. В этом случае, если выходной сигнал положительный, мы считаем, что нейрон «сработал», а иначе — нет. Этот нейрон эквивалентен неравенству «зеленый — красный — 0,5> 0». Если это соответствует истине (то есть зеленый свет включен, а красный свет выключен), то машина должна ехать.
В реальных нейронных сетях искусственные нейроны делают еще один шаг. После суммирования взвешенных входов и сложения смещения нейрон применяет нелинейную функцию активации. Популярным выбором является сигмовидная функция, S-образная функция, которая всегда выдает значение от 0 до 1.
Использование функции активации не изменит результат нашей простой модели стоп-сигнала (за исключением того, что нам нужно будет использовать порог 0,5 вместо 0). Но нелинейность функций активации необходима для того, чтобы нейронные сети могли моделировать более сложные функции. Без функции активации каждая нейронная сеть, какой бы сложной она ни была, была бы сведена к линейной комбинации ее входов. А линейная функция не может моделировать сложные явления реального мира. Нелинейные функции активации позволяют нейронным сетям аппроксимировать любую математическую функцию .
Пример сети
Конечно, есть много способов приблизить функции. Что делает нейронные сети особенными, так это то, что мы знаем, как «обучать» их, используя немного исчисления, кучу данных и массу вычислительной мощности. Вместо того, чтобы человек-программист напрямую проектировал нейронную сеть для конкретной задачи, мы можем создать программное обеспечение, которое запускается с довольно общей нейронной сети, просматривает кучу помеченных примеров, а затем модифицирует нейронную сеть так, чтобы она вырабатывала правильную метку как можно больше помеченных примеров. Надежда состоит в том, что итоговая сеть будет обобщаться, создавая правильные метки для примеров, ранее не входивших в ее обучающий набор.
Процесс достижения этой точки начался задолго до AlexNet. В 1986 году три исследователя опубликовали заметную статью о обратном распространении, методике, которая помогла сделать его математически пригодным для обучения сложных нейронных сетей.
Чтобы понять, как работает обратное распространение, давайте рассмотрим простую нейронную сеть, описанную Майклом Нильсеном в его превосходном онлайн-учебнике по глубокому обучению. Цель этой сети — взять изображение размером 28 × 28 пикселей, представляющее рукописную цифру, и правильно определить, является ли цифра 0, 1, 2 и т. Д.
Каждое изображение имеет 28 × 28 = 784 входных значений, каждое из которых представляет собой действительное число от нуля до единицы, представляющее, насколько светлый или темный пиксель. Нильсен построил нейронную сеть, которая выглядела так:
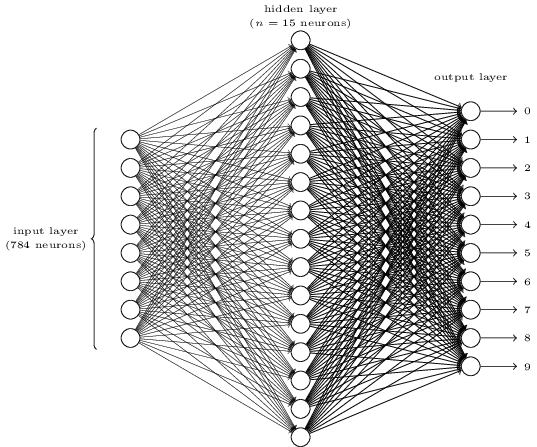
На этом изображении каждый из кругов в среднем и правом столбцах представляет собой нейрон, подобный тому, который мы рассматривали в предыдущем разделе. Каждый нейрон получает средневзвешенное значение своих входов, добавляет значение смещения, а затем применяет функцию активации. Обратите внимание, что кружки слева не являются нейронами — эти кружки представляют входные значения сети. В то время как изображение показывает только 8 входных кругов, фактически есть 784 входных сигнала — по одному на каждый пиксель входных изображений.
Предполагается, что каждый из 10 нейронов справа «загорается» для другой цифры: верхний нейрон должен срабатывать, когда входное изображение имеет рукописный 0 (и не иначе), второй должен срабатывать, когда сеть видит рукописный текст. 1 (и не иначе) и пр.
Каждый нейрон получает данные от каждого нейрона в слое перед ним. Таким образом, каждый из 15 нейронов в среднем слое имеет 784 входных значения. Каждый из этих 15 нейронов имеет весовой параметр для каждого из 784 входов. Это означает, что один этот слой имеет 15 × 784 = 11 760 весовых параметров. Аналогично, выходной слой содержит 10 нейронов, каждый из которых получает вход от каждого из 15 нейронов в среднем слое, добавляя еще 15 × 10 = 150 весовых параметров. Кроме того, сеть также имеет 25 переменных смещения — по одной для каждого из 25 нейронов.
Цель обучения — настроить эти 11 935 параметров, чтобы максимизировать вероятность того, что правильный выходной нейрон — и только этот выходной нейрон — загорится, когда показано изображение рукописной цифры. Мы можем сделать это, используя хорошо известный набор данных под названием MNIST, который обеспечивает 60000 изображений с разрешением 28 × 28 пикселей:

Нильсен показывает, как обучить эту сеть, используя всего 74 строки обычного кода Python — никаких специальных библиотек машинного обучения не требуется. Обучение начинается с выбора случайных значений для каждого из этих 11 935 параметров веса и смещения. Затем программа просматривает примеры изображений, выполняя двухэтапный процесс для каждого:
- Опережающий шаг вычисляет выходные значения сети, учитывая входное изображение и текущие параметры сети.
- Обратное распространение шаг вычисляет , сколько результаты расходились от правильных выходных значений, а затем изменяют параметры сети, чтобы слегка повысить его производительность на этом конкретном входном изображении.
Вот пример. Предположим, что в сети показано это изображение:
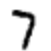
Если сеть хорошо откалибрована, то выход «7» сети должен быть близок к 1, тогда как все остальные девять выходов сети должны быть близки к 0. Но вместо этого предположим, что «0» вывод сети равен 0,8, когда показано это изображение , Это слишком высоко! Обучающий алгоритм изменит входные веса выходного нейрона «0», чтобы приблизить его к 0, когда в следующий раз будет показано это конкретное изображение.
Для этого алгоритм обратного распространения вычисляет градиент ошибки для каждого входного весового параметра. Это мера того, насколько изменится ошибка на выходе для данного изменения веса на входе. Затем алгоритм использует этот градиент, чтобы решить, насколько изменить каждый входной вес — чем больше градиент, тем больше этот параметр изменяется.
Другими словами, процесс обучения «учит» нейроны в выходном слое уделять меньше внимания входам (то есть нейронам в среднем слое), которые подталкивают их к неправильному ответу, и уделять больше внимания входам, которые подталкивают их правильное направление.
Алгоритм повторяет этот шаг для каждого из других выходных нейронов. Он уменьшает вес входов для нейронов «1», «2», «3», «4», «5», «6», «8» и «9» (но не нейрон «7») до нажмите значение этих выходных нейронов вниз. Чем выше значение входа, тем больше градиент ошибки вывода по отношению к весовому параметру этого входа — следовательно, чем больше его вес будет уменьшен.
И наоборот, алгоритм обучения увеличивает веса входов до выхода «7», что заставит этот нейрон производить более высокое значение в следующий раз, когда ему будет показано это конкретное изображение. Еще раз, входы с большими значениями будут видеть большее увеличение их весов, в результате чего выходной нейрон «7» будет уделять больше внимания этим входам в будущих раундах.
Затем алгоритм должен выполнить те же вычисления для среднего уровня: изменить каждый входной вес в направлении, которое уменьшит ошибки сети — опять же, получая значение «7» ближе к 1, а остальные ближе к 0. Но каждый средний нейрон является входом для всех 10 нейронов в выходном слое, что усложняет ситуацию двумя способами.
Во-первых, градиент ошибки для любого заданного входного значения среднего уровня зависит не только от этого входного значения, но также от градиентов ошибок в следующем слое. Алгоритм называется обратным распространением, поскольку градиенты ошибок от более поздних уровней в сети распространяются в обратном направлении и используются (вместе с правилом цепочки из исчисления) для вычисления градиентов в более ранних слоях.
Кроме того, каждый нейрон среднего слоя является входом для всех десяти нейронов в выходном слое. Таким образом, алгоритм обучения должен вычислять градиент ошибки, отражающий то, как изменение определенного входного веса повлияет на среднюю ошибку по всем выходным данным.
Обратное распространение является алгоритмом восхождения на холм: каждый раунд алгоритма приводит к тому, что выходные данные приближаются к правильным результатам для этого тренировочного образа, но только немного ближе. Поскольку алгоритм рассматривает все больше и больше примеров, он «поднимается в гору» к оптимальному набору параметров, который правильно классифицирует как можно больше обучающих примеров. Достижение высокой точности требует тысяч обучающих примеров, и алгоритму, возможно, потребуется пройтись по каждому изображению в этом обучающем наборе десятки раз, прежде чем производительность перестанет улучшаться.
Нильсен показывает, как реализовать все это с помощью всего 74 строк кода Python. Примечательно, что нейронная сеть, обученная с помощью этой простой программы, способна распознавать более 95 процентов рукописных цифр в базе данных MNIST. С некоторыми дополнительными усовершенствованиями простая двухслойная нейронная сеть способна распознавать более 98 процентов цифр.
Прорыв AlexNet
Возможно, вы ожидали, что развитие обратного распространения в 1980-х годах положит начало быстрому прогрессу в машинном обучении на основе нейронных сетей, но этого не произошло. Конечно, некоторые люди работали над техникой в 1990-х и начале 2000-х годов. Но интерес к нейронным сетям на самом деле не взлетел до начала 2010-х годов.
Мы можем видеть это по результатам конкурса ImageNet , ежегодного конкурса по машинному обучению, организованного Стэнфордским ученым-компьютерщиком Фэй-Фей Ли. На соревнованиях каждого года участникам давали общий набор из более чем миллиона тренировочных образов, каждый из которых был помечен одной из примерно 1000 возможных категорий, таких как «пожарная машина», «гриб» или «гепард». Программное обеспечение участников оценивалось по его способности классифицировать другие изображения, которые не были включены в тренировочный набор. Программы могли выдвигать несколько догадок и считаться успешными, если одна из первых пяти догадок для изображения соответствовала метке, выбранной человеком.
Конкурс начался в 2010 году, и глубокие нейронные сети не играли главной роли первые два года. Лучшие команды использовали множество других методов машинного обучения с довольно посредственными результатами. Победившая команда в 2010 году имела топ-5 ошибок в 28 процентов. В 2011 году было 25 процентов.
Затем наступил 2012 год. Эта команда из Университета Торонто представила запись, которуювпоследствии назвали AlexNet в честь ведущего автора Алекса Крижевского, и взорвала конкурентов из воды. Используя глубокую нейронную сеть, команда достигла 16-процентного уровня ошибок из пяти лучших. У ближайшего конкурента в этом году был 26-процентный процент ошибок.
Сеть распознавания почерка, рассмотренная выше, имела два слоя, 25 нейронов и почти 12 000 параметров. AlexNet был значительно больше и сложнее: восемь обучаемых слоев, 650 000 нейронов и 60 миллионов параметров.
Обучение сети такого размера требовало огромных вычислительных мощностей, и AlexNet был разработан, чтобы использовать преимущества мощной параллельной вычислительной мощности, предоставляемой современными графическими процессорами. Исследователи выяснили, как разделить работу по обучению своей сети на два графических процессора, предоставив им вдвое большую вычислительную мощность для работы. Тем не менее, несмотря на активную оптимизацию, обучение сети заняло от пяти до шести дней с использованием оборудования, доступного в 2012 году (пара графических процессоров Nvidia GTX 580, каждый с 3 ГБ памяти).
Полезно взглянуть на некоторые примеры результатов AlexNet, чтобы оценить, какой это был впечатляющий прорыв. Вот снимок из бумаги, показывающий несколько изображений и топ-5 классификаций AlexNet:

AlexNet смог распознать, что первое изображение содержало клеща, даже несмотря на то, что клещ имел небольшую форму на самом краю изображения. Программное обеспечение не только правильно идентифицировало леопарда, но и другие его догадки — ягуара, гепарда, снежного барса и египетского кота — были похожими кошками. AlexNet пометил изображение гриба «агариком» — типом гриба. «Гриб», официально правильный лейбл, был вторым выбором AlexNet.
«Ошибки» AlexNet были почти такими же впечатляющими. На нем была надпись «Далматин», изображающая далматина позади некоторых вишен, тогда как на официальном ярлыке была «вишня». AlexNet признал, что картина содержала какие-то фрукты — «виноград» и «бузина» были среди его пяти лучших вариантов — но он не совсем понял, что это были вишни. Показанная фотография мадагаскарской кошки на дереве, AlexNet перечислила группу мелких млекопитающих, лазающих по деревьям. Многие люди (включая меня) ошиблись бы с этим.
Это была действительно впечатляющая производительность, демонстрирующая, что программное обеспечение может распознавать общие объекты в самых разных ориентациях и настройках. Глубокие нейронные сети быстро стали самой популярной техникой для задач распознавания изображений, и с тех пор мир машинного обучения не оглядывался назад.
«После успеха метода глубокого обучения в 2012 году подавляющее большинство записей в 2013 году использовали глубокие сверточные нейронные сети», — пишут спонсоры ImageNet . Эта модель продолжалась в последующие годы, и более поздние победители основывались на базовых методах, впервые примененных командой AlexNet. К 2017 году участники, использующие гораздо более глубокие нейронные сети, опустили пятерку лучших ошибок ниже трех процентов. Учитывая сложность задачи, это, вероятно, делает компьютеры лучше в этой задаче, чем многие люди.

Сверточные сети: концепция
Технически, AlexNet был сверточной нейронной сетью. В этом разделе я объясню, что делает сверточная сеть и почему этот метод стал решающим для современных алгоритмов распознавания изображений.
Простая сеть распознавания рукописного ввода, которую мы исследовали ранее, была полностью подключена: каждый нейрон в первом слое является входом для каждого нейрона во втором слое. Эта структура работает достаточно хорошо для относительно простой задачи распознавания цифр на небольших изображениях размером 28 × 28 пикселей. Но это плохо масштабируется.
В наборе рукописных цифр MNIST символы всегда центрированы. Это значительно упрощает обучение, потому что это означает, что (например) семерка всегда будет иметь несколько темных пикселей сверху и справа от изображения, тогда как нижний левый всегда всегда белый. У ноля почти всегда будет белое пятно около среднего и более темные пиксели около краев. Простая, полностью подключенная сеть может довольно легко обнаруживать подобные шаблоны.
Но предположим, что вы хотели построить нейронную сеть, которая могла бы распознавать числа, которые могут быть расположены в любом месте на большом изображении. Полностью подключенная сеть также не будет работать, потому что у нее нет эффективного способа распознать сходство между формами, расположенными в разных частях изображения. Если в вашем тренировочном наборе оказалось большинство семерок в верхнем левом углу, то вы получите сеть, которая лучше распознает семерки в верхнем левом углу, чем где-либо еще на изображении.
Теоретически вы можете решить эту проблему, убедившись, что в вашем тренировочном наборе много примеров каждой цифры в каждой возможной позиции пикселя. Но на практике это было бы чрезвычайно расточительно. По мере увеличения размера изображений и глубины сетей количество соединений — и, следовательно, количество входных весовых параметров — будет расти. Вам понадобится намного больше обучающих изображений (не говоря уже о гораздо большей вычислительной мощности), чтобы достичь адекватной точности.
Когда нейронная сеть учится распознавать фигуру в одной позиции на изображении, она должна быть в состоянии применить эту обучаемость для распознавания аналогичных фигур в других частях изображения. Сверточные нейронные сети обеспечивают элегантное решение этой проблемы.
«Это как взять трафарет или узор и сопоставить его с каждым пятном на изображении», — говорит исследователь ИИ Цзе Тан. «У вас есть трафаретный рисунок собаки, и вы в основном сопоставляете верхний правый угол с вашим трафаретом — есть ли там собака? Если нет, вы перемещаете трафарет немного. Вы делаете это по всему изображению». Неважно, где на изображении появляется собака. Трафарет будет соответствовать ей. Вы не хотите, чтобы каждый подраздел сети изучал свой отдельный классификатор собак «.
Итак, представьте, что мы взяли большое изображение и разбили его на квадраты 28 × 28 пикселей. Затем мы могли бы подать каждый квадрат в полностью подключенную сеть распознавания рукописного ввода, которую мы исследовали ранее. Если выход «7» загорелся хотя бы для одного из этих квадратов, это признак того, что изображение в целом, вероятно, содержит семерку. Это по сути то, что делают сверточные сети.
В сверточных сетях эти «трафареты» известны как детекторы признаков, а область, на которую они смотрят, называется рецептивным полем. Реальные детекторы имеют тенденцию иметь восприимчивые поля намного меньше, чем 28 пикселей на стороне. В AlexNet первый сверточный слой имел детекторы признаков, восприимчивое поле которых было 11 пикселей на 11 пикселей. Последующие сверточные слои в AlexNet имели рецептивные поля шириной три или пять единиц.
Когда детектор объектов проходит по входному изображению, он создает карту объектов: двумерную сетку, которая показывает, насколько сильно детектор был активирован различными частями изображения. Сверточные слои, как правило, имеют более одного детектора признаков, каждый из которых сканирует входное изображение по разному шаблону. В AlexNet первый слой имел 96 детекторов признаков и создал 96 карт характеристик.

Чтобы сделать это более конкретным, вот визуальное представление визуальных шаблонов, изученных каждым из 96 детекторов функций в первом слое AlexNet после обучения по сети. Есть детекторы, которые ищут горизонтальные или вертикальные линии, градиенты от светлого до темного, шахматные узоры и многие другие формы.
Цветное изображение обычно представляется в виде карты пикселей с тремя числами для каждого пикселя: красным значением, зеленым значением и синим значением. Первый слой AlexNet берет это трехзначное представление изображения и преобразует его в 96-значное представление. Каждый «пиксель» в этом изображении имеет 96 значений, по одному для каждого из 96 детекторов признаков.
В этом примере первое из этих 96 значений указывает, соответствует ли конкретная точка на изображении этому шаблону:

Второе значение указывает, соответствует ли конкретная точка этому шаблону:

Третье значение указывает, соответствует ли конкретная точка этому шаблону:

… и так далее для остальных 93 детекторов функций в первом слое AlexNet. Первый слой выводит новое представление изображения, где каждый «пиксель» представляет собой вектор из 96 чисел (как я объясню позже, это новое представление также уменьшается в четыре раза).
Так что это первый слой AlexNet. Далее идут еще четыре сверточных слоя, каждый из которых принимает выходные данные предыдущего слоя.
Как мы уже видели, первый слой обнаруживает базовые шаблоны, такие как горизонтальные и вертикальные линии, градиенты от света к темноте и кривые. Затем второй слой использует их как строительные блоки для обнаружения чуть более сложных форм. Например, второй слой может иметь детектор объектов, который находит круги, объединяя выходные данные детекторов объектов первого уровня, которые находят кривые. Третий слой находит еще более сложные формы, комбинируя элементы второго слоя. Четвертый и пятый слои находят еще более сложные узоры.
Исследователи Мэтью Цейлер и Роб Фергус опубликовали отличную статью 2014 года, в которой предлагаются некоторые полезные способы визуализации видов паттернов, распознаваемых пятислойной нейронной сетью, аналогичной ImageNet.
В этом слайд-шоу из их бумаги каждое изображение имеет две половины. Справа вы увидите примеры миниатюрных изображений, которые сильно активировали детектор определенных функций. Они организованы в группы по девять человек — каждая группа соответствует определенному детектору. Слева находится карта, которая показывает, какие именно пиксели в этом миниатюрном изображении были наиболее ответственны за сильное совпадение. Вы можете увидеть это наиболее ярко в пятом слое, так как есть детекторы функций, которые сильно загораются для собак, корпоративные логотипы, колеса одноколесного велосипеда и так далее.





Просматривая изображения, вы можете увидеть, что каждый слой способен распознавать более сложные узоры, чем те, что были до него. Первый слой распознает простые образцы пикселей, которые совсем не похожи. Второй слой распознает текстуры и простые формы. На третьем слое мы видим узнаваемые формы, такие как автомобильные колеса и красновато-оранжевые сферы (это могут быть помидоры, божьи коровки или что-то еще).
Первый уровень имеет восприимчивое поле 11 единиц на стороне, в то время как более поздние уровни имеют рецептивные поля, которые составляют от трех до пяти единиц на стороне. Но помните, эти более поздние слои смотрят на карты объектов, сгенерированные более ранними слоями, и каждый «пиксель» в этих картах объектов представляет несколько пикселей в исходном изображении. Таким образом, восприимчивое поле каждого слоя охватывает большую часть исходного изображения, чем слои, которые предшествовали ему. Это одна из причин того, что миниатюрные изображения в более поздних слоях кажутся более сложными, чем в более ранних слоях.
Пятый и последний уровень сети способен распознавать впечатляюще широкий спектр элементов в этих изображениях. Например, взгляните на это изображение, которое я вытащил из правого верхнего угла изображения слоя пять выше:

Девять изображений справа могут выглядеть не очень похожими. Но если вы посмотрите на девять тепловых карт слева, вы увидите, что этот конкретный детектор объектов не фокусируется на объектах на переднем плане каждого изображения. Вместо этого он фокусируется на травянистых частях на фоне каждого изображения!
Очевидно, что детектор травы полезен, если одна из категорий, которую вы пытаетесь идентифицировать, это «трава», но это, вероятно, будет полезно и для многих других категорий. Следуя пяти сверточным слоям, AlexNet имеет три слоя, которые полностью связаны, как слои в нашей сети распознавания рукописного ввода. Эти слои рассматривают каждую из карт объектов, созданных пятым сверточным слоем, когда они пытаются классифицировать изображение в одну из 1000 возможных категорий.
Так что, если на заднем плане картинка с травой, скорее всего, это дикое животное. С другой стороны, если на заднем плане картина с травой, это менее вероятно, что она будет изображением мебели в помещении. Эти и другие детекторы пятого уровня предоставляют обширную информацию о том, что, вероятно, на фотографии. Последние несколько уровней сети синтезируют эту информацию, чтобы получить обоснованное предположение о том, что изображает картина в целом.
Что отличает сверточные слои: общие входные веса
Мы видели, что детекторы функций в сверточных слоях выполняют впечатляющее распознавание образов, но до сих пор я не объяснил, как на самом деле работают сверточные сети.
Сверточный слой — это слой нейронов. Как и любые нейроны, они берут средневзвешенное значение своих входов и затем применяют функцию активации. Параметры обучаются с использованием методов обратного распространения, которые мы обсуждали.
Но, в отличие от описанных выше нейронных сетей, сверточный слой не полностью связан. Каждый нейрон получает вход только от небольшой доли нейронов в предыдущем слое. И, что особенно важно, нейроны в сверточных сетях имеют общие входные веса.
Давайте увеличим первый нейрон в первом сверточном слое AlexNet. Этот слой имеет восприимчивое поле 11 × 11 пикселей, поэтому первый нейрон смотрит на квадрат 11 × 11 пикселей в одном углу изображения. Этот нейрон получает входные данные от этих 121 пикселя, и каждый пиксель имеет три значения — красное, зеленое и синее. Таким образом, нейрон имеет в общей сложности 363 входа. Как и любой нейрон, этот принимает средневзвешенное значение этих 363 входных значений, а затем применяет функцию активации. А поскольку он имеет 363 входных значения, ему также необходимо 363 входных весовых параметра.
Второй нейрон в первом слое AlexNet очень похож на первый. Он также смотрит на квадрат 11 × 11 пикселей, но его рецептивное поле смещено на четыре пикселя от рецептивного поля первого нейрона. Это создает семипиксельное перекрытие между двумя рецептивными полями, что позволяет избежать пропуска интересных паттернов, если они пересекают линию между двумя нейронами. Этот второй нейрон также принимает 363 значения, которые описывают его квадрат 11 × 11 пикселей, умножает каждое значение на весовой параметр, складывает эти значения и применяет функцию активации.
Вместо того чтобы иметь собственный набор из 363 входных весов, второй нейрон использует те же входные веса, что и первый нейрон. Верхний левый пиксель первого нейрона использует те же входные веса, что и верхний левый пиксель второго нейрона. Таким образом, два нейрона ищут один и тот же паттерн; у них просто есть рецептивные поля, которые смещены друг от друга на четыре пикселя.
Конечно, существует более двух нейронов: на самом деле в сетке 55 × 55 размещено 3025 нейронов. Каждый из этих 3025 нейронов использует тот же набор из 363 входных весов, что и первые два нейрона. Вместе все эти нейроны образуют детектор признаков, который «сканирует» определенный шаблон, где бы он ни находился на изображении.
Помните, что первый слой AlexNet имел 96 детекторов функций. 3025 нейронов, которые я только что упомянул, составляют один из этих 96 детекторов признаков. Каждый из 95 детекторов функций представляет собой отдельную группу из 3025 нейронов. Каждая группа из 3025 нейронов делит свои 363 входных веса с другими в своей группе, но не с нейронами в других 95 детекторах признаков.
Сверточные сети обучаются с использованием того же базового алгоритма обратного распространения, который используется для обучения полностью подключенных сетей, но сверточная структура делает процесс обучения более эффективным и действенным.
«Использование сверток действительно полезно, потому что вы можете повторно использовать параметры», — сказал Ars эксперт по машинному обучению и автор Sean Gerrish. Это значительно сокращает количество входных весов, которые должна изучить сеть, что позволяет сети получать лучшие результаты с меньшим количеством обучающих примеров.
Изучение одной части изображения может привести к лучшему распознаванию того же шаблона в других местах на других изображениях. Это позволяет сети достигать высокой производительности с гораздо меньшим количеством обучающих примеров.
Люди быстро осознали силу глубоких сверточных сетей
Статья AlexNet была сенсацией в академическом сообществе машинного обучения, но ее значение также быстро было признано в промышленности. Google особенно заинтересовался этой техникой.
В 2013 году Google приобрел стартап, созданный авторами статьи AlexNet. Они использовали эту технологию, чтобы добавить новую функцию поиска изображений в Google Фото. «Мы взяли передовые исследования прямо из академической исследовательской лаборатории и запустили их всего за шесть месяцев», — пишет Чак Розенберг из Google .
Между тем, в газете 2013 года описывалось, как Google использовал глубокие сверточные сети для считывания номеров адресов из фотографий в изображениях Google Street View. «Наша система помогла нам извлечь около 100 миллионов физических номеров улиц из изображений Street View», — пишут авторы.
Исследователи обнаружили, что производительность нейронных сетей продолжала улучшаться по мере их углубления. «Мы обнаруживаем, что производительность этого подхода увеличивается с глубиной сверточной сети, при этом лучшая производительность достигается в самой глубокой архитектуре, которую мы обучали», — пишет команда Google Street View. «Наши эксперименты показывают, что более глубокие архитектуры могут получить лучшую точность с уменьшением отдачи».
Так что после AlexNet нейронные сети становились все глубже. Команда Google представила победившую запись в конкурсе ImageNet 2014 года — всего через два года после победы AlexNet в 2012 году. Как и AlexNet, она была основана на глубоко сверточной нейронной сети, но Google использовала гораздо более глубокую 22-слойную сеть для достижения 6,7- процент ошибок в топ-5 — значительное улучшение по сравнению с 16-процентной ошибкой AlexNet.
Тем не менее, более глубокие сети были полезны только с большими тренировочными наборами. По этой причине Джерриш утверждает, что набор данных ImageNet и конкуренция сыграли ключевую роль в обеспечении успеха глубоких сверточных сетей. Помните, что конкурс ImageNet дал участникам миллион изображений и попросил распределить их по одной из 1000 различных категорий.
«Наличие миллиона изображений для обучения вашей сети означает, что в каждом классе 1000 изображений», — сказал Джерриш. По его словам, без такого большого набора данных у вас было бы слишком много параметров для обучения сети.
В последние годы особое внимание уделялось накоплению больших объемов данных для обучения более глубоким и точным сетям. Это серьезная причина, по которой компании, занимающиеся самостоятельным вождением автомобилей, так много внимания уделяют накоплению миль на дорогах общего пользования — изображения и видео, полученные в результате испытаний, отправляются обратно в штаб-квартиру и используются для обучения сетей распознавания изображений компаний.
Глубокий компьютерный бум
Открытие того факта, что более глубокие сети и большие обучающие наборы могут обеспечить лучшую и лучшую производительность, создало ненасытную потребность в большей вычислительной мощности. Большая часть успеха AlexNet заключалась в осознании того, что обучение нейронной сети связано с матричными операциями, которые можно эффективно выполнять с использованием высокопараллельных вычислительных мощностей графической карты.
«Нейронные сети распараллеливаются», — говорит исследователь машинного обучения Цзе Тан. Видеокарты, которые обеспечивают мощную параллельную вычислительную мощность для видеоигр, оказались полезными для нейронных сетей.
«Базовая работа графических процессоров, по-настоящему быстрое умножение матриц, стала основной работой нейронных сетей», — сказал Тан.
Это превратилось в бонус для Nvidia и AMD, ведущих производителей графических процессоров. Обе компании работали над созданием новых микросхем, которые настроены на уникальные потребности приложений машинного обучения, и теперь приложения ИИ составляют значительную долю продаж GPU этих компаний.
В 2016 году Google объявила, что она создала специальный чип под названием Tensor Processing Unit (TPU) специально для операций с нейронными сетями. «Хотя Google рассматривал возможность создания специализированной интегральной схемы (ASIC) для нейронных сетей еще в 2006 году, ситуация стала актуальной в 2013 году, — писал Google в прошлом году.« Именно тогда мы поняли, что быстрорастущие вычислительные требования нейронных сетей могут потребовать от нас удвоить количество центров обработки данных, которые мы эксплуатируем ».
Первоначально доступ к TPU был ограничен собственными сервисами Google, но позже Google начал разрешать кому-либо использовать технологию через платформу облачных вычислений Google.
Конечно, Google не единственная компания, работающая над искусственным интеллектом. Просто для небольшой выборки: последние версии чипов iPhone включают «нейронный движок», оптимизированный для работы нейронной сети. Intel разрабатывает собственную линейку чипов, оптимизированных для глубокого обучения. Тесла недавно объявила, что она выбрасывает чипы Nvidia в пользу доморощенного чипа нейронной сети. Как сообщается, Amazon также работает над собственным чипом AI .
Почему глубокие нейронные сети трудно понять
Я объяснил, как работают глубокие нейронные сети, но я не совсем объяснил, почему они работают так же, как и они. Более чем загадочно то, как ошеломляюще большое количество матричных вычислений может позволить компьютерной системе отличить ягуара от гепарда и бузины от смородины.
Возможно, самая замечательная вещь в нейронных сетях — то, что они не делают. Свертки позволяют нейронным сетям понимать переводы — они могут определить, похож ли шаблон в верхнем правом углу одного изображения на шаблон в верхнем левом углу другого.
Но помимо этого, сверточные сети не имеют реального понимания геометрии. Они не могут распознать, что одно изображение похоже на другое, если оно повернуто на 45 градусов или увеличено в два раза. Сверточные сети не делают попыток понять трехмерные объектные структуры, и они не могут корректировать для меняющихся условий освещения.
Тем не менее, глубокие нейронные сети могут распознавать изображения собак, взяты ли они спереди или сбоку, и занимают ли они небольшую часть изображения или большую. Как они это делают? Оказывается, что при наличии достаточного количества данных статистический подход грубой силы достаточно хорош, чтобы выполнить работу. Сверточная сеть не предназначена для того, чтобы «представить», как будет выглядеть конкретное изображение, если смотреть под другим углом или при других обстоятельствах, но с достаточным количеством помеченных примеров она может изучить все возможные перестановки путем простого повторения.
Есть доказательства того, что зрительная система человека на самом деле работает аналогичным образом. Рассмотрим эту пару картинок (убедитесь, что вы внимательно смотрите на первое изображение, прежде чем переходить ко второму):


{kind=link}
Очевидно, создатель этого изображения взял чей-то образ и перевернул глаза и рот вверх ногами. Изображение выглядит относительно нормальным, когда вы смотрите на него с ног на голову, потому что зрительная система человека привыкла видеть глаза и рот в этой ориентации. Но когда вы смотрите на лицо правой стороной вверх, лицо сразу выглядит странно деформированным.
Это говорит о том, что зрительная система человека опирается на те же грубые методы сопоставления с образцом, что и нейронные сети. Если мы смотрим на что-то, что почти всегда рассматривается в одной ориентации — как человеческие глаза — мы гораздо лучше распознаем их в их обычной ориентации.
Нейронные сети хороши в использовании всего контекста в изображении, чтобы выяснить, что он показывает. Например, автомобили обычно появляются на дорогах. Платья обычно появляются либо на женских телах, либо висят в шкафах. Самолеты кажутся либо обрамленными голубым небом, либо выруливают на взлетно-посадочную полосу. Никто явно не обучает нейронные сети этим корреляциям, но с достаточным количеством отмеченных примеров сеть может изучить их автоматически.
В 2015 году некоторые исследователи Google попытались лучше понять нейронные сети, «запустив их назад». Вместо того, чтобы использовать картинки для обучения нейронных сетей, они использовали обученную нейронную сеть для модификации изображений. Например, они начали с изображения, которое содержало случайный шум, а затем постепенно модифицировали его, чтобы сильно «засветить» один из выходов нейронной сети — фактически попросив нейронную сеть «нарисовать» одну из категорий, которым она была обучена. признать. В одном захватывающем случае у них была нейронная сеть, генерирующая картинки, которые сильно активировали бы нейронную сеть, которая была обучена распознавать гантели.

«Там хорошо есть гантели, но, кажется, ни одна фотография гантели не будет полной без мышц-тяжелоатлетов, чтобы поднять их», — пишут исследователи Google.
Опять же, это может показаться странным на первый взгляд, но на самом деле это не сильно отличается от того, что делают люди. Если мы видим небольшой или размытый объект на изображении, мы смотрим на окружающую среду, чтобы понять, что может происходить на изображении. Люди явно рассуждают об изображениях по-разному, опираясь на наше глубокое концептуальное понимание окружающего нас мира. Но в конечном счете, глубокие нейронные сети хороши в распознавании изображений, потому что они в полной мере используют весь контекст, показанный на картинке, который ничем не отличается от того, как это делают люди.
[thumbs-rating-buttons]