Где применяется NLP
Сегодня быстро растет количество полезных приложений в этой области:
- поиск (письменный или устный);
- показ подходящей онлайн рекламы;
- автоматический (или при содействии) перевод;
- анализ настроений для задач маркетинга;
- распознавание речи и чат-боты,
- голосовые помощники (автоматизированная помощь покупателю, заказ товаров и услуг).
Обработка естественного языка (Natural Language Processing, NLP) — общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза естественных языков. Применительно к искусственному интеллекту анализ означает понимание языка, а синтез — генерацию грамотного текста. Решение этих проблем будет означать создание более удобной формы взаимодействия компьютера и человека.
Немного из истории из хорошей статьи на Дзене тоже про ML и ИИ
Так как темы взаимопроникающие, далее я поясню почему, то немного истории ИИ. Ещё в 1950 году в философском журнале Mind был описан тест Тьюринга — эмпирический тест, идея которого была предложена Аланом Тьюрингом в статье «Вычислительные машины и разум». Тьюринг задался целью определить, может ли машина мыслить.
В 1956 году, на Дартмундской летней конференции, Рей Соломонофф написал отчёт о вероятностной машине, обучающейся без учителя, назвав её: «Индуктивная машина вывода».
В СССР большой в клад в развитие искусственного интеллекта внёс Д.А. Поспелов, который с 1968 года занялся исследованиями в этой области. Им был впервые в мире разработан подход к принятию решений, опирающийся на семиотические (логико-лингвистические) модели, который послужил теоретической основой ситуационного управления большими системами. Он создал теорию «наивных» псевдофизических логик, моделирующих рассуждения «здравого смысла» о времени, пространстве, действиях, каузальных цепочках и т.д., которая обеспечивает реализацию в интеллектуальных системах рассуждений о закономерностях физического мира и действиях в нем.
Может ли компьютер понять человека
Разработчик Адам Гитги опубликовал статью, в которой описал принципы NLP и рассказал о создании программы для извлечения информации и текста на языке программирования Python. У него все подробно и добротно!
С момента появления компьютеров программисты пытаются научить их понимать «человеческие» языки. Люди изобрели письменность тысячи лет назад, и было бы очень удобно, если бы компьютер мог считать и проанализировать накопленную за этот период информацию.
Компьютеры пока что не способны воспринимать английский на уровне человека, но и уже достигнутые ими успехи действительно впечатляют. В отдельных областях технологии NLP позволяют сэкономить исследователям массу времени. Последние разработки в сфере обработки естественного языка свободно доступны в таких открытых библиотеках на Python, как spaCy, textacy и neuralcoref. С помощью нескольких строк кода можно буквально творить чудеса.
Извлечение смысла из текста — сложный процесс
Процесс чтения и понимания английского языка очень непрост, не говоря уже о том, что в нём нет жёстко упорядоченных и логичных норм. Например, вот эта фраза:
«Environmental regulators grill business owner over illegal coal fires»
В английском языке слово «grill» помимо прямого значения «жарить» имеет значение «допросить с пристрастием». Вызывает сомнение, в каком смысле — прямом или переносном — использовали его авторы заголовка. Понять, что именно сделали с бизнесменом органы охраны природы, компьютеру будет очень проблематично.
Чтобы выполнить задачи такой сложности с использованием машинного обучения (МО), обычно строится конвейер. Задача разбивается на несколько очень небольших частей, после чего модели МО решают каждую подпроблему по отдельности. Далее модели соединяются в конвейер, по которому обмениваются информацией, что даёт возможность решать задачи очень высокой сложности. Именно так происходит обработка естественных языков.
Пошаговое построение NLP-конвейера
Вот отрывок из статьи о Лондоне из Википедии:
«London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.»
В этом абзаце есть несколько содержательных фактов. Чтобы компьютер смог обнаружить их, прочитав текст, сначала нужно обучить его базовым принципам письменного языка.
Шаг 1: сегментация на предложения
В первую очередь необходимо разбить текст на отдельные предложения:
- London is the capital and most populous city of England and the United Kingdom.
- Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia.
- It was founded by the Romans, who named it Londinium.
Можно допустить, что каждое предложение на английском несёт законченную мысль или идею. Гораздо проще написать программу для понимания одного предложения, чем всего абзаца сразу.
Разработать модель сегментации на предложения несложно: их границы обычно обозначены точками. Но современные NLP-конвейеры часто используют более прогрессивные методы, которые срабатывают даже на плохо отформатированных документах.
Шаг 2: лексический анализ
После разделения текста на предложения, нужно по очереди проанализировать их, начиная с первого:
«London is the capital and most populous city of England and the United Kingdom.»
Теперь необходимо разложить это предложение на отдельные слова, или лексемы. Этот процесс называется «лексическим анализом». Таким образом, получены элементы:
«London», «is», «the», «capital», «and», «most», «populous», «city», «of», «England», «and», «the», «United», «Kingdom», «.»
В естественных языках провести эту операцию тоже нетрудно: слова в предложении отделяются пробелами. Знаки препинания считаются отдельными единицами, так как тоже имеют смысл.
Шаг 3: частеречная разметка
Далее нужно попытаться определить, к какой части речи относится каждая из лексем: существительное, глагол, прилагательное и так далее. Знание того, какую роль то или иное слово выполняет в предложении, поможет прояснить значение предложения.
Это можно сделать, введя каждое из слов (а также несколько стоящих рядом слов, чтобы не вырывать его из контекста) в уже обученный классификатор по частям речи:

Изначально модель тренировалась на миллионах предложений на английском языке, в которых у каждого слова уже была обозначена часть речи, — она должна была научиться по аналогии выполнять эту операцию самостоятельно.
Такие модели опираются исключительно на статистику: они не воспринимают значение слов так, как это делают люди. Они просто угадывают части речи на основе схожих предложений и слов, которые они видели раньше.
Результаты, полученные после анализа всего предложения:

Эта информация позволяет понемногу восстановить смысл фраз. Очевидно, что в предложении присутствуют слова «London» и «capital» — модель может предположить, что речь идёт о Лондоне.
Шаг 4: лемматизация текста (определение начальной формы слов)
В английском, как и в большинстве языков, слова имеют несколько различных форм. Например:
I had a pony.
I had two ponies.
В обоих предложениях употребляется одно существительное «pony», но с разными окончаниями. При обработке текста компьютеру очень полезно знать исходные формы используемых слов, чтобы понимать, что в обоих предложениях речь идёт об одном и том же предмете. Иначе строки «pony» и «ponies» он воспримет как два не связанных между собой слова.
В NLP этот процесс определения начальной формы, или леммы, каждого слова в предложении имеет название «лемматизация».
То же делают и с глаголами. Их также можно лемматизировать, то есть выделить исходную, неспрягаемую форму. Поэтому, предложение «I had two ponies» можно представить как «I [have] two [pony]».
Определение лемм компьютер обычно выполняет по справочным таблицам форм слов, характерных для частей речи, и иногда — набора некоторых правил обработки незнакомых слов.
Вот так будет выглядеть предложение после лемматизации — выделения основной формы глагола:

Единственное изменение в том, что «is» превратилось в «be».
Шаг 5: выявление стоповых слов (слов, которые не несут самостоятельного смысла)
Далее нужно определить смысловую нагрузку слов в предложении. В английском языке присутствует большое число слов-заполнителей, таких как союзы и артикли («and», «the», «a»). При статистическом анализе текста эти слова создают много шума, потому что встречаются значительно чаще других слов. Некоторые NLP-конвейеры идентифицируют их как «стоповые слова», которые перед проведением анализа необходимо опустить. Вот как после этого будет выглядеть предложение:

Эти слова обычно просто проверяют по встроенному списку уже знакомых системе стоповых слов. Но универсального списка таких лишних слов, применимого для всех случаев, не существует: они могут различаться в зависимости от ситуации применения.
Например, при создании поискового движка рок-групп нужно, чтобы система не выбрасывала артикль «the», потому что он встречается во многих названиях. В 1980-х годах была даже группа под названием «The The!»
Шаг 6: синтаксический анализ на основе грамматики зависимостей
Теперь необходимо выяснить, как связаны друг с другом слова в предложении. Для этого проводят синтаксический анализ на основе грамматики (или дерева) зависимостей.
Цель — построить дерево, в котором к каждому слову соответствует одно непроизводное слово. Корень дерева — это ключевой глагол предложения. Вот так будет выглядеть дерево синтаксического анализа вначале:
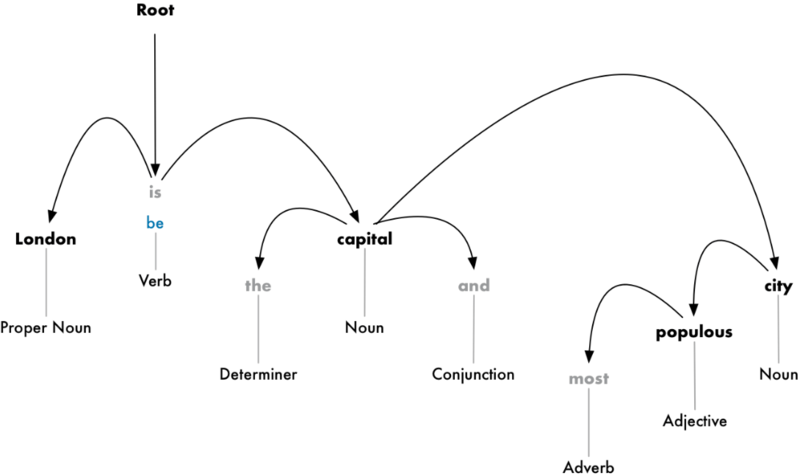
Но можно пойти дальше: помимо подбора непроизводных слов, можно вычислить тип взаимосвязи между двумя словами в предложении:

Из этого дерева видно, что подлежащим в предложении является слово «London», которое связано со словом «capital» через слово «be». Удалось выделить значимую информацию: Лондон — это столица. Продолжив анализ, можно выяснить, что Лондон является столицей Соединённого Королевства.
Аналогично тому, как выше модель МО угадывала, к какой части речи относятся слова, для парсинга зависимостей в модель вводят слова и получают некий результат на выходе. Анализ связей между словами — весьма трудоёмкая задача, подробного описания которой хватит на целую отдельную статью. Начать можно со статьи «Parsing English in 500 Lines of Python» Мэтью Хоннибала.
Хотя в 2015 году этот подход считался общепринятым, на сегодняшний день он уже устарел и больше не используется даже самим автором. В 2016 году Google выпустила новый анализатор зависимостей Parsey McParseface, превосходящий остальные инструменты благодаря новому подходу на основе глубокого обучения, который быстро набрал популярность в отрасли. Годом позже компания даже выпустила новую, ещё более совершенную модель ParseySaurus. Таким образом, технологии синтаксического анализа не стоят на месте и постоянно улучшаются.
Важно отметить, что многие предложения на английском языке могут толковаться двояко и нелегко поддаются анализу. В таких случаях модель просто делает предположение, исходя из того, какой вариант ей кажется более вероятным. Но этот способ имеет свои недостатки, так как иногда ответы моделей достаточно далеки от истины. На сайте spaCy можно запустить синтаксический анализ на основе дерева зависимостей для любого предложения.
Шаг 6.1: поиск именных групп
Пока что каждое слово в предложении рассматривалось обособленно от остальных. Но иногда гораздо полезнее группировать слова, которые передают единую мысль или понятие. Для автоматической группировки таких слов можно использовать результаты дерева синтаксического анализа.
Например, вместо
можно объединить именные группы:

Необходимость выполнения этого шага зависит от конечной цели исследования. Но часто это позволяет быстро и просто разложить предложение на части, если не требуется уточнять, к каким частям речи относятся слова, и вместо этого сосредоточиться на общей идее.
Шаг 7: выделение именованных сущностей (named entity recognition, NER)
После парсинга грамматики можно перейти к извлечению смысла текста. В предложении есть следующие имена существительные:

Некоторые из них обозначают объекты реального мира. Например, «London», «England» и «United Kingdom» — это географические названия конкретных мест на карте, которые модель должна уметь опознавать. Зная это, с помощью NLP можно автоматически сгенерировать список реальных мест, упомянутых в предложении.
Цель выделения именованных сущностей — найти эти существительные и маркировать по типу реальных объектов, с которыми они соотносятся, например, в рассматриваемом предложении — как «географические сущности». Вот так будет выглядеть предложение после того, как каждая лексема пройдёт через NER-модель:

Однако NER-системы не просто сверяются со словарём. Они используют контекст (окружение слова в предложении) а также статистическую модель, чтобы определить тип объекта, обозначаемого существительным. Качественные NER-системы с учётом контекста способны, например, отличить актрису Бруклин Деккер от района Бруклин в Нью-Йорке.
Системы выделения именованных сущностей могут присваивать им различные метки, например:
- имена людей
- названия компаний
- географические объекты (на физических и политических картах)
- наименования продуктов
- дата и время
- денежные суммы
- названия событий
NER-системы имеют множество применений, потому что позволяют запросто структурировать представленные в тексте данные при обработке естественных языков. Самостоятельно опробовать модели выделения именованных сущностей также можно на сайте spaCy.
Шаг 8: разрешение кореференции
На данном этапе уже получено много полезной информации о предложении: части речи каждого слова, взаимосвязи между словами и какие из них являются именами собственными.
Однако в естественных языках также присутствует множество местоимений. Они помогают сократить речь, заменяя повторяющиеся существительные. Человек понимает, к какому существительному относится то или иное местоимение из контекста. Но модель обработки естественного языка этого не знает, потому что исследует по одному предложению за раз.
Если проанализировать с помощью NLP-конвейера третье предложение в тексте:
«It was founded by the Romans, who named it Londinium»,
то система увидит, что «it» был основан римлянами. Но при этом ей необходимо понять, что римлянами был основан именно Лондон.
Когда предложение читает человек, он сразу понимает, что местоимение заменяет город. Цель разрешения кореференции — соотнести местоимения в тексте с существительными, на которые они указывают, и найти все местоимения, которые указывают на один и тот же предмет.
Вот результат этой операции для слова «Лондон» в рассмотренном тексте:

Если полученную информацию обобщить с деревом синтаксического анализа и данными об именованных сущностях, это значительно приблизит модель к пониманию смысла всего текста.
Разрешение кореференции — один из наисложнейших этапов всего процесса обработки естественного языка, даже сложнее, чем синтаксический анализ. Новейшие подходы в сфере глубокого обучения обеспечивают более высокую точность, но и они всё же имеют свои недостатки. Подробнее об этом можно прочитать здесь.
А более детально разобраться с разрешением кореференции можно на сайте Hugging Face.
За последние 20 лет математическая лингвистика превратилась в захватывающую область научных исследований, а также в практически применимую технологию: она всё чаще используется в бытовой технике (например, в приложениях Apple Siri и Skype Translator). Четыре ключевых фактора способствовали такому развитию: (1) значительно увеличилась вычислительная мощность компьютеров, (2) стало доступно большое количество лингвистических данных, (3) были изобретены высокоэффективные методы машинного обучения (machine learning, ML), и (4) улучшилось понимание структуры человеческого языка и его использования в социальных контекстах. В этом обзоре мы опишем некоторые интересные области применения технологий обработки естественного языка (ОЕЯ, natural language processing), использующих подход больших данных (big data), основанный на современных передовых методологиях и объединяющий статистический анализ, и машинное обучение с пониманием естественного языка.
Математическая лингвистика, также известная как обработка естественного языка, является подполем компьютерной науки, использующим вычислительные технологии для исследования, понимания и создания контента на человеческом языке. У компьютерных лингвистических систем множество практических применений. Они могут помогать общению между людьми, например, осуществлять перевод с одного естественного языка на другой; способствовать взаимопониманию людей и машин, — эту функцию выполняют разговорные агенты типа Siri; приносить пользу как людям, так и машинам, анализируя и изучая огромное количество контента на человеческом языке, доступное в интернете.
В течение первых нескольких десятилетий учёные пытались адаптировать словари и правила человеческих языков для компьютеров. Это оказалось трудной задачей из-за изменчивости, двусмысленности и зависимости интерпретации человеческих языков от контекста. Например, star (звезда) может быть либо астрономическим объектом, либо человеком; может быть как существительным, так и глаголом (в английском языке). Другой пример: у заголовка Teacher strikes idle kids возможны две интерпретации — «учитель бьёт ленивых детей» и «забастовки учителей заставляют детей бездельничать». Интерпретация будет зависеть от того, какой смысл мы вкладываем в существительное, глагол и прилагательное в предложении, как мы понимаем грамматическую структуру. Начиная с 1980-х годов, но более широко в 1990-х, в ОЕЯ произошли значительные изменения: исследователи начали строить модели на большом количестве эмпирических языковых данных. Основанная на статистике, или на корпусной лингвистике, ОЕЯ стала одной из первых успешных областей использования больших данных (задолго до того, как машинное обучение получило широкое применение, даже до появления термина «большие данные»).
Центральной находкой статистического подхода к ОЕЯ стало то, что простые методы, использующие шаблоны из слов и последовательностей частей речи, часто показывают хорошие результаты при обучении на большом количестве данных. Многие классификаторы текстов и детекторы эмоциональной окраски по-прежнему основаны исключительно на наборах слов (подход bag of words), они не учитывают структуру дискурса и предложений, или значение текста. Достичь значительных улучшений по сравнению с результатами этого подхода может быть непросто, но это возможно с помощью нейронных сетей. Наиболее эффективные системы сейчас основываются на подходах машинного обучения и на лучшем понимании лингвистической структуры. В настоящее время доступны высокопроизводительные инструменты, способные выделять из текста синтаксическую, семантическую и дискурсивную информацию. Одним из примеров является Stanford CoreNLP, который предоставляет стандартную последовательность процедур предварительной обработки текста, включающую разметку частей речи (существительное, глагол и предлог); идентификацию имён собственных, таких как люди, места и организации; анализ грамматической структуры предложения; определение согласования между местоимениями и существительными (рис.1).

Два фактора превратили ОЕЯ в область использования больших данных. Первый — это ранняя доступность лингвистической информации в цифровой форме, в частности через Консорциум лингвистических данных (Linguistic Data Consortium, LDC), созданный в 1992-м году. В настоящий момент большое количество текстов в электронном формате можно легко загрузить из интернета. Обширные корпусы текстов и прямой речи доступны в лингвистически аннотированной форме — данные размечены с помощью меток частей речи, синтаксического и семантического разбора; в них аннотированы имена собственные (лица, места, организации), намерения диалога (утверждение, вопрос, запрос), эмоции и положительные или отрицательные чувства; определена тема или риторика текста. Второй фактор — усовершенствование методов ОЕЯ было стимулировано соревнованиями на базе «открытых задач» (задач, решать которые предложено всем, кто хочет). Первоначально эти соревнования финансировались и организовывались Министерством обороны США, но позже инициативу по организации взяло на себя исследовательское сообщество (например, оно организовало соревнование CoNLL Shared Tasks). Такие конкурсы были предшественниками современных соревнований в области прогнозирования и аналитических моделей на основе машинного обучения, таких как Kaggle, в которых компании и исследователи публикуют данные и статистику, которую они получили эмпирически, а специалисты в области глубинного анализа данных (data mining) со всего мира соревнуются, кто эти данные лучше обработает.
Сегодня основным ограничением ОЕЯ является то, что большинство ресурсов и систем ОЕЯ доступны только для высокоресурсных языков (High Resource Language, HRL — таких языков, для которых накоплено много данных), таких как английский, французский, испанский, немецкий и китайский. Многие языки с низким уровнем ресурсов (Low Resource Language, LRL), такие как бенгальский, индонезийский, панджабский, себуано и суахили, на которых говорят и пишут миллионы людей, не имеют таких ресурсов и систем. Вопрос, который будет стоять в будущем перед языковым сообществом — это как разработать ресурсы и инструменты ОЕЯ для сотен или тысяч разных языков, а не ограничиться парой-тройкой языков.
Машинный перевод
Владение языками традиционно было отличительной чертой образованных людей. Несмотря на то, что социальное значение этого навыка сошло на нет в эпоху науки и машин, перевод между языками остаётся крайне важной задачей. Машинный перевод, пожалуй, является лучшим способом компьютерной помощи общению между людьми. Более того, способность компьютеров переводить с языка на язык является одним из лучших показателей машинного интеллекта: для правильного перевода необходимо не только уметь анализировать и создавать предложения на человеческих языках, но и иметь понимание мировых знаний и контекстов (и всё это — на человеческом уровне). Также требуется уметь правильно выбирать между вариантами в случаях, где встречается двусмысленность. Например, французское слово bordel («бордель») в переводе означает публичный дом, но если кто-то скажет: «в моей комнате такой бордель», автоматический переводчик должен понять, что этот человек не содержит притон в своей комнате, а скорее всего имеет в виду, что в его комнате беспорядок.
Машинный перевод был одной из первых «нечисловых» задач для компьютеров: методы разрабатывались с конца 1950-х годов. Однако системы ОЕЯ ранних десятилетий, построенные вручную на базе грамматик, добились очень ограниченного успеха. В начале 1990-х годов, когда исследователи из IBM получили большое количество параллельных предложений на английском и французском языке от двуязычного канадского парламента (документацию его деятельности), ситуация изменилась. Полученный корпус параллельного текста позволил собрать статистику перевода последовательностей слов и построить на этой базе вероятностную модель машинного перевода.
После затишья конца 1990-х годов, новое тысячелетие принесло комбинацию других благоприятных факторов. Это, во-первых, доступность большого количества интерактивного текста (в том числе, параллельного текста на двух языках); во-вторых, это распространённость и сравнительная дешевизна вычислительных систем; а в-третьих, появление новой идеи построения систем машинного перевода на базе фразовой статистики. Ключевое нововведение ОЕЯ этого времени — следующее: вместо того, чтобы переводить слово за словом, стали переводить небольшие группы слов, которые часто имеют характерное значение. Например, японское выражение mizu iro буквально представляет собой последовательность из двух слов («вода цвет»), но это — неправильный смысл. Выражение также не означает тип живописи — акварельный рисунок, оно обозначает светло-голубой оттенок. Такой основанный на фразовых значениях машинный перевод был использован Францем Охом (Franz Josef Och) в разработке переводчика Google Translate.
Такая технология легла в основу сервисов, которые мы используем сейчас, и которые обеспечивают свободный и мгновенный перевод между многими языками. К сожалению, этот перевод всё ещё недостаточно точный, его хватает лишь для задачи определения общего смысла текста на уровне абзаца. Многочисленные последующие исследования пытались улучшить использование структуры предложений естественного языка (то есть их синтаксиса) в системах машинного перевода, разработать более глубокие смысловые представления языка.
В 2014 году мы стали свидетелями появления чрезвычайно перспективного решения вопроса машинного перевода с помощью технологий глубокого обучения. Центральная идея глубокого обучения заключается в том, что, если научить модель с несколькими уровнями представления оптимизировать конечную цель (например, качество перевода), тогда модель сама сможет строить промежуточные представления, специфические для конкретных задач. Эта идея была реализована на моделях нейронных сетей, в которых информация хранится в векторах с вещественными числами. Над векторами выполняют некоторые операции, а именно матричное умножение, за которым следует нелинейное преобразование (например, к ним применяется сигмоидальная функция, которая отображает выходные значения матричного умножения на множество [−1, 1]). Построение больших моделей такого типа — гораздо более практично (особенно если учитывать, что сейчас стали возможны широкомасштабные параллельные вычисления на графических процессорах). В области перевода, исследования сосредоточились на определённом типе нейронных сетей — с долгой краткосрочной памятью (long short-term memory, LSTM). Эти сети могут лучше запоминать контекстную информацию по ходу «чтения» предложения (рис.2). Нейронные сети часто очень эффективны для нахождения тонких семантических сходств. Нейросетевые системы машинного перевода уже дали результаты, сравнимые по качеству с другими лучшими способами машинного перевода.
С момента написания статьи было совершено несколько ключевых открытий, одно из которых — изобретение Google Neural Machine Translation. Главное достижение этого метода по сравнению с другими системами машинного перевода — GNMT может переводить с языка на язык без помощи языка-посредника. Раньше, в статистических системах перевода, процедура занимала несколько шагов. Допустим, нам надо перевести текст с языка суахили на язык йоруба. Тогда на первой стадии текст переводился на английский, и с английского — на йоруба. Этого можно избежать с GNMT без потерь в качестве. Но это мы уже имели в простых системах нейронного машинного перевода, чем тогда GNMT лучше? Основная проблема до недавнего времени заключалась в том, что для каждой пары языков нужно было создавать отдельную нейронную сеть (то есть нейронные системы машинного перевода с трудом поддавались масштабированию). В противоположность, GNMT может работать с любой парой языков с помощью одной нейросети. GNMT также переводит лучше, чем статистические системы машинного перевода. Такая способность была получена благодаря особенному виду внутреннего состояния сети, которое в новостях красноречиво назвали «универсальным языком», и которое Google называет zero-shot translation.
По-прежнему малоисследованная область машинного перевода — это вопрос, как снабдить машины лучшим пониманием дискурса, чтобы предложения в переводе согласовывались друг с другом. Но работа в этой области уже началась. Наконец, машинный перевод не обязательно должен осуществляться машиной в одиночку. Скорее, он может быть переосмыслен как возможность совместной работы человека и компьютера (машинная помощь человеку-переводчику). В такой системе, компьютерный интеллект может быть использован в роли интерфейса взаимодействия человека и машины, он будет давать полезные советы и продуктивно реагировать на то, что человек подал на вход (вместо того, чтобы полностью заменить навыки и знания человека-переводчика).
В русском языке есть следующие проблемы NLP
Качество понимания зависит от множества факторов: от языка, от национальной культуры, от самого собеседника и т. д. Вот некоторые примеры сложностей, с которыми сталкиваются системы понимания текстов.
- Сложности с раскрытием анафор (распознаванием, что имеется в виду при использовании местоимений): предложения «Мы отдали бананы обезьянам, потому что они были голодные» и «Мы отдали бананы обезьянам, потому что они были перезрелые» похожи по синтаксической структуре. В одном из них местоимение они относится к обезьянам, а в другом — к бананам. Правильное понимание зависит от знаний компьютера, какими могут быть бананы и обезьяны.
- Свободный порядок слов может привести к совершенно иному толкованию фразы: «Бытие определяет сознание» — что определяет что?
- В русском языке свободный порядок компенсируется развитой морфологией, служебными словами и знаками препинания, но в большинстве случаев для компьютера это представляет дополнительную проблему.
- В речи могут встретиться неологизмы, например, глагол «Пятидесятирублируй» — то есть высылай 50 рублей. Система должна уметь отличать такие случаи от опечатоки правильно их понимать.
- Правильное понимание омонимов — ещё одна проблема. При распознавании речи, помимо прочих, возникает проблема фонетических омонимов. Во фразе «Серый волк в глухом лесу встретил рыжую лису» выделенные слова слышатся одинаково, и без знания, кто глухой, а кто рыжий, не обойтись (кроме того, что лиса может быть рыжей, а лес — глухим, лес также может быть рыжим (характеристика, в данном случае обозначающая преобладающий цвет листвы в лесу), в то время как лиса может быть глухой, что порождает дополнительную проблему, вытекающую из предыдущей, хотя и отчасти компенсируется морфологией — у прилагательных в данном предложении род явно разный).
Под обработкой естественных языков (Natural Language Processing, NLP) понимается создание систем, обрабатывающих или “понимающих” язык с целью выполнения определенных задач. Эти задачи могут включать:
- Формирование ответов на вопросы (Question Answering) (то, что делают Siri, Alexa и Cortana)
- Анализ эмоциональной окраски высказываний (Sentiment Analysis) (определение, имеет ли высказывание положительную или отрицательную коннотацию)
- Нахождение текста, соответствующего изображению (Image to Text Mappings) (генерация подписи к входному изображению)
- Машинный перевод (Machine Translation) (перевод абзаца текста с одного языка на другой)
- Распознавание речи (Speech Recognition)
- Морфологическая разметка (Part of Speech Tagging) (определение частей речи в предложении и их аннотирование)
- Извлечение сущностей (Name Entity Recognition)
Традиционный подход к NLP предполагал глубокое знание предметной области – лингвистики. Понимание таких терминов, как фонемы и морфемы, было обязательным, так как существуют целые дисциплины лингвистики, посвященные их изучению. Посмотрим, как традиционное NLP распознало бы следующее слово:

Допустим, наша цель – собрать некоторую информацию об этом слове (определить его эмоциональную окраску, найти его значение и т.д.). Используя наши знания о языке, мы можем разбить это слово на три части.

Мы понимаем, что приставка (prefix) un- означает отрицание, и знаем, что -ed может означать время, к которому относится данное слово (в данном случае – прошедшее время). Распознав значение однокоренного слова interest, мы легко можем сделать вывод о значении и эмоциональной окраске всего слова. Вроде бы просто. Тем не менее, если принять во внимание все многообразие приставок и суффиксов английского языка, понадобится очень умелый лингвист, чтобы понять все возможные комбинации и их значения.
Пример, показывающий количество приставок суффиксов и корней в английском языке
Как использовать глубокое обучение
В основе глубокого обучения лежит обучение представлениям. Например, сверточные нейронные сети (Convolutional Neural Network, CNN) включают в себя объединение различных фильтров, предназначенных для классификации объектов по категориям. Здесь мы попытаемся применить похожий подход, создавая представления слов в больших наборах данных.
Векторы слов
Так как глубокое обучение не может жить без математики, представим каждое слово в виде d-мерного вектора. Возьмем d=6.
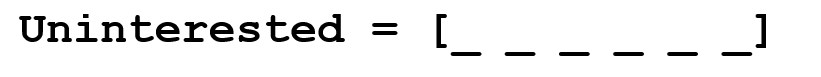
Теперь подумаем, как заполнить значения. Мы хотим, чтобы вектор был заполнен таким образом, чтобы он каким-то образом представлял слово и его контекст, значение или семантику. Один из способов – построить матрицу совместной встречаемости (cooccurrence matrix). Рассмотрим следующее предложение:
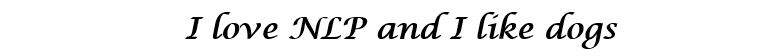
Мы хотим получить векторное представление для каждого слова.
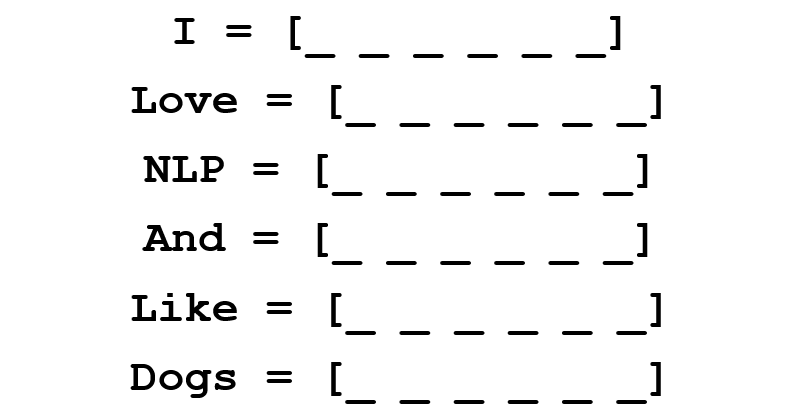
Матрица совместной встречаемости содержит количество раз, которое каждое слово встретилось в корпусе (обучающем наборе) после каждого другого слова этого корпуса.

Строки этой матрицы могут служить в качестве векторных представлений наших слов.

Обратите внимание, что даже из этой простой матрицы мы можем почерпнуть довольно важные сведения. Например, заметим, что векторы слов “love” и “like” содержат единицы в ячейках, отвечающих за их соседство с существительными (“NLP” и “dogs”). У них также стоит “1” там, где они соседствуют с “I”, показывая, что это слово, скорее всего, глагол. Можете себе представить, насколько проще выявлять подобные схожие черты, когда набор данных больше, чем одно предложение: в этом случае векторы таких глаголов, как “love”, “like” и других синонимов, будут похожи, так как эти слова будут использоваться в схожих контекстах.
Хорошо для начала, но здесь мы обращаем внимание, что размерность вектора каждого слова будет линейно возрастать в зависимости от размера корпуса. В случае миллиона слов (что немного для стандартных задач NLP), мы получили бы матрицу размерности миллион на миллион, которая, к тому же, была бы очень разреженной (с большим количеством нулей). Это определенно не лучший вариант с точки зрения эффективности хранения данных. В вопросе нахождения оптимального векторного представления слов было сделано несколько серьезных подвижек. Самая известная из них – Word2Vec.
Word2Vec
Главная цель всех методов инициализации вектора слова – хранить в этом векторе как можно больше информации, сохраняя разумную размерность (в идеале, от 25 до 1000). В основе Word2Vec лежит идея научиться прогнозировать окружающие слова для каждого слова. Рассмотрим предложение из предыдущего примера: “I love NLP and I like dogs”. Сейчас нас интересуют только три первые слова. Пусть размер нашего окна и будет равен трем.

Теперь мы хотим взять центральное слово “love” и предсказать слова, идущие до и после него. Как же мы это осуществим? Конечно же, с помощью максимизации и оптимизации функции! Формально наша функция пытается максимизировать логарифмическую вероятность каждого слова-контекста для текущего центрального слова.
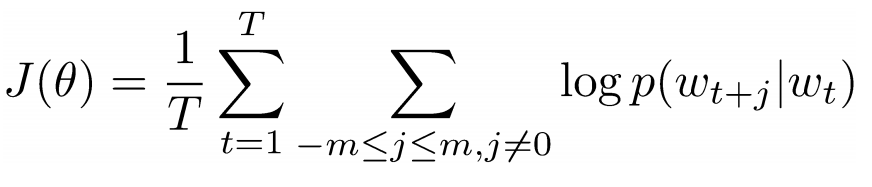
Изучим вышеприведенную формулу подробнее. Из нее следует, что мы будем складывать логарифмическую вероятность совместной встречаемости как “I” и “love”, так и “NLP” и “love” (в обоих случаях “love” – центральное слово). Переменная T означает количество обучающих (training) предложений. Рассмотрим логарифмическую вероятность поближе.

Vc – векторное представление центрального слова. У каждого слова есть два векторных представления: Uo и Uw, одно для случая, когда слово занимает центральную позицию, другое для случая, когда это слово – “внешнее”. Векторы обучаются методом стохастического градиентного спуска. Это определенно одно из самых трудных для понимания уравнений, так что если вам все еще трудно представить себе, что происходит, можно найти дополнительную информацию здесь и здесь.
Подытожим одним предложением: Word2Vec ищет векторные представления различных слов, максимизируя логарифмическую вероятность встречаемости слов контекста для данного центрального слова и преобразуя векторы методом стохастического градиентного спуска.
(Дополнительно: дальше авторы работы подробно рассказывают о том, как с помощью негативного семплирования (negative sampling) и взятия подвыборок (subsampling) можно получить более точные векторы слов).
Пожалуй, самым интересным вкладом Word2Vec в развитие NLP стало появление линейных отношений между разными векторами слов. После обучения векторы отражают различные грамматические и семантические концепции.
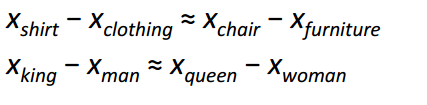
Удивительно, как такая простая целевая функция и несложная техника оптимизация смогли выявить эти линейные отношения.
Бонус: еще один классный метод инициализации векторов слов – GloVe (Global Vector for Word Representation) (сочетает идеи матрицы совместной встречаемости с Word2Vec).
Рекуррентные нейронные сети (Recurrent Neural Networks, RNN)
Теперь посмотрим, как с нашими векторами будет работать рекуррентная нейронная сеть. RNN – палочка-выручалочка для большинства современных задач обработки естественного языка. Главное преимущество RNN в том, что они могут эффективно использовать данные с предыдущих шагов. Вот так выглядит маленький кусочек RNN:
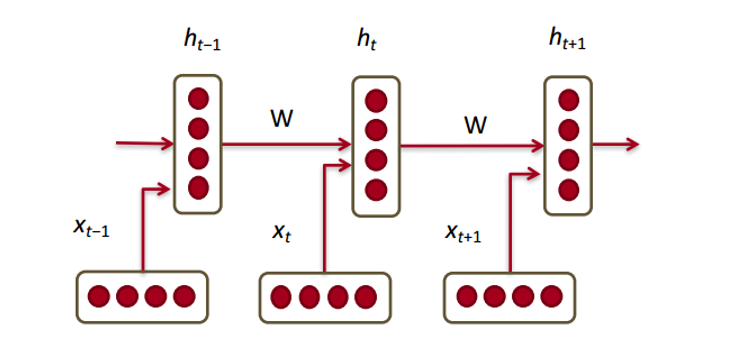
Внизу изображены векторы слов (xt,xt−1,xt+1). У каждого вектора на каждом шаге есть скрытый вектор состояния (hidden state vector) (ht,ht−1,ht+1). Будем называть эту пару модулем (module).
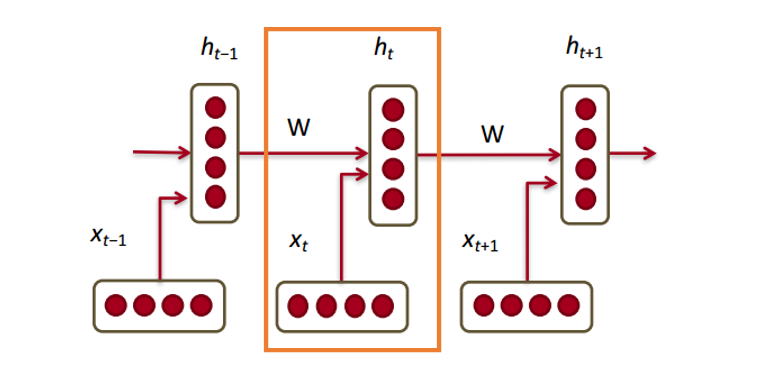
Скрытое состояние в каждом модуле RNN – это функция от вектора слова и вектора скрытого состояния с прошлого шага.

Если мы приглядимся к верхним индексам, то увидим, что здесь есть матрица весов Whx, которую мы умножаем на входное значение, и есть рекуррентная матрица весов Whh, которая умножается на вектор скрытого состояния с предыдущего шага. Имейте в виду, что эти рекуррентные матрицы весов на каждом шаге одинаковы. Это ключевой момент RNN. Если тщательно обдумать, то этот подход значительно отличается от, скажем, традиционных двухслойных нейронных сетей. В этом случае у нас обычно выбирается отдельная матрица W для каждого слоя: W1 и W2. Здесь же рекуррентная матрица весов одна и та же для всей сети.
Для получения выходных значений каждого модуля (Yhat) служит еще одна матрица весов – Ws, умноженная на h.
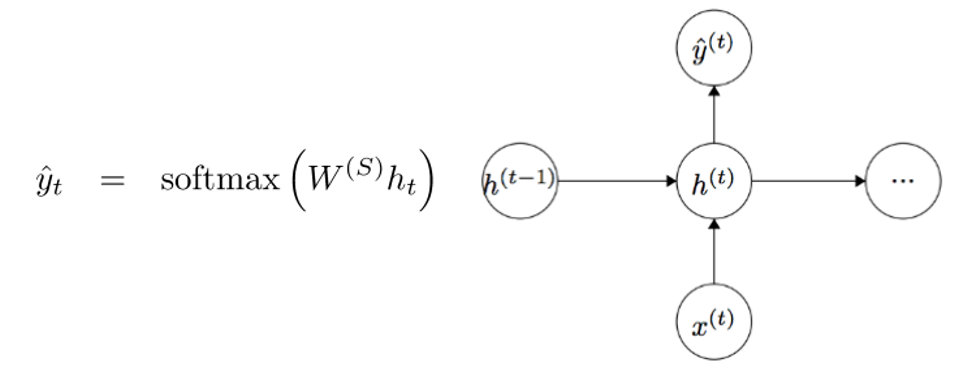
Теперь давайте посмотрим со стороны и поймем, в чем состоят преимущества RNN. Наиболее явное отличие RNN от традиционной нейронной сети в том, что RNN принимает на вход последовательность входных данных (в нашем случае слов). Этим они отличаются, например, от типичных CNN, на вход которым подается целое изображение. Для RNN же входными данными может служить как короткое предложение, так и сочинение из пяти абзацев. Кроме того, порядок, в котором подаются данные, может влиять на то, как в процессе обучения меняются матрицы весов и векторы скрытых состояний. К концу обучения в векторах скрытых состояний должна накопиться информация из прошлых шагов.
Управляемые рекуррентные нейроны (Gated recurrent units, GRU)
Теперь давайте познакомимся с понятием управляемого рекуррентного нейрона, с помощью которых производится вычисление векторов скрытых состояний в RNN. Такой подход позволяет сохранять информацию о более отдаленных зависимостях. Давайте порассуждаем о том, почему отдаленные зависимости для обычных RNN могут стать проблемой. В время работы метода обратного распространения ошибки (backpropagation) ошибка будет двигаться по RNN от последнего шага к самому раннему. При достаточно малом начальном градиенте (скажем, менее 0.25) к третьему или четвертому модулю градиент почти исчезнет (так как по правилу производной сложной функции градиенты будут перемножаться), и тогда скрытые состояния самых первых шагов не обновятся.
В обычных RNN вектор скрытых состояний вычисляется по следующей формуле:
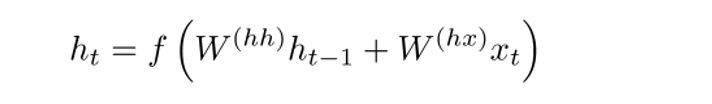
Метод GRU позволяет вычислять h(t) иначе. Вычисления разбиваются на три блока: фильтр обновления (update gate), фильтр сброса состояния (reset gate) и новый контейнер памяти (memory container). Обы фильтра – функции от входного векторного представления слова и скрытого состояния на предыдущем шаге.

Главное отличие состоит в том, что для каждого фильтра используются свои веса. Это обозначено разными верхними индексами. Фильтр обновления использует Wz и Uz, а фильтр сброса состояния – Wr и Ur.
Теперь рассчитаем контейнер памяти:
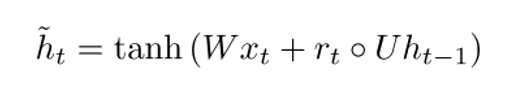
(пустой кружок здесь обозначает произведение Адамара).
Теперь, если присмотреться к формуле, то можно заметить, что если множитель фильтра сброса состояния близок к нулю, то и все произведение также приблизится к нулю, и таким образом, информация из предыдущего шага ht−1 не будет учтена. В этом случай нейрон – всего лишь функция от нового вектора слова xt−1.
Окончательную формулу h(t) можно записать как
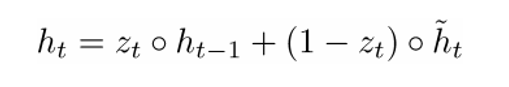
ht – функция от всех трех компонентов: фильтра обновления, фильтра сброса состояния и контейнера памяти. Можно лучше понять это, визуализируя, что происходит с формулой, когда zt близится к 1 и когда zt близко к 0. В первом случай вектор скрытого состояния ht в большей степени зависит от предыдущего скрытого состояния, а текущий контейнер памяти не принимается во внимание, так как (1 – zt) стремится к 0. Когда же zt близится к 1, новый вектор скрытого состояния ht, наоборот, зависит в основном от контейнера памяти, а предыдущее скрытое состояние не учитывается. Итак, наши три компонента можно интуитивно описать следующим образом:
- Фильтр обновления
- Если zt ~ 1, то ht не принимает во внимание текущий вектор слова и просто копирует предыдущее скрытое состояние.
- Если zt ~ 0, то ht не учитывает предыдущее скрытое состояние и зависит только от контейнера памяти.
- Этот фильтр позволяет модели контролировать, как много информации от предыдущего скрытого состояния должно влиять на текущее скрытое состояние.
- Фильтр сброса состояния
- Если rt ~ 1, то контейнер памяти сохраняет информацию с предыдущего скрытого состояния.
- Если rt ~ 0, то контейнер памяти не учитывает предыдущее скрытое состояние.
- Этот фильтр позволяет отбросить часть информации, если в будущем она не будет нас интересовать.
- Контейнер памяти: зависит от фильтра сброса состояния.
Приведем пример, иллюстрирующий работу GRU. Допустим, у нас есть следующие несколько предложений:

и вопрос: “Чему равна сумма двух чисел?” Так как предложение посередине никак не влияет на ответ, фильтры сброса и обновления позволят модели “забыть” это предложение и понять, что изменять скрытое состояние может только определенная информация (в данном случае, числа).
Нейроны с длительной кратковременной памятью (Long short-term memory, LSTM)
Если вы разобрались с GRU, то LSTM не составит для вас трудности. LSTM также состоит из последовательности фильтров.
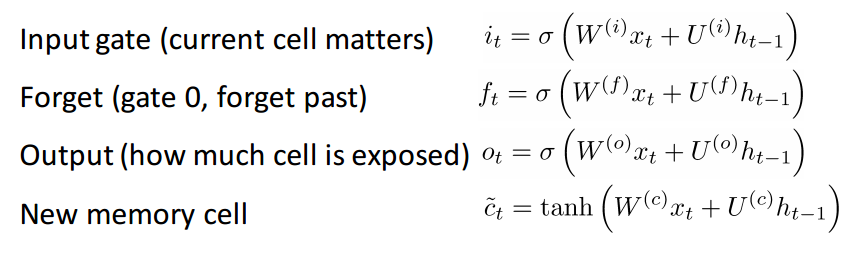
LSTM определенно принимает на вход больше информации. Так как ее можно считать расширением GRU, я не буду разбирать ее подробно, а чтобы получить детальное описание каждого фильтра и каждого шага вычислений, вы можете обратиться к прекрасно написанному блог-посту Криса Олаха (Chris Olah). На текущий момент это самый популярный тьюториал по LSTM, и точно поможет тем из вас, кто ищет понятное и интуитивное объяснение работы этого метода.
Сравнение LSTM и GRU
Сначала рассмотрим общие черты. Оба эти метода разработаны для того, чтобы сохранять отдаленные зависимости в последовательностях слов. Под отдаленными зависимостями имеются в виду такие ситуации, когда два слова или фразы могут встретиться на разных временных шагах, но отношения между ними важны для достижения конечной цели. LSTM и GRU отслеживают эти отношения с помощью фильтров, которые могут сохранять или сбрасывать информацию из обрабатываемой последовательности.
Различие между двумя методами состоит в количестве фильтров (GRU – 2, LSTM – 3). Это влияет на количество нелинейностей, которое приходит от входных данных и в конечном итоге влияет на процесс вычислений. Кроме того, в GRU отсутствует ячейка памяти ct, как в LSTM.
Нейронный машинный перевод (Neural Machine Translation, NMT)
Введение
Последняя работа, которую мы сегодня рассмотрим, описывает подход к решению задачи машинного перевода. Авторы этой работы – специалисты Google по машинному обучению Джефф Дин (Jeff Dean), Грег Коррадо (Greg Corrado), Ориал Виньялс (Orial Vinyals) и другие – представляют систему машинного обучения, которая лежит в основе широко известного сервиса Google Translate. С введением этой системы количество ошибок перевода сократилось в среднем на 60% по сравнению с прежней системой, используемой Google.
Традиционные подходы к автоматическому переводу включают в себя нахождение пофразовых соответствий. Этот подход требовал хорошего знания лингвистики и в конце концов оказался недостаточно стабильным и неспособным к генерализации. Одна из проблем традиционного подхода состояла в том, что исходное предложение переводилось по кусочкам. Оказалось, что переводить все предложение за раз (как это делает NMT) более эффективно, так как в этом случае вовлекается более широкий контекст и порядок слов становится более естественным.
Архитектура сети
Авторы этой статьи описывают глубокую сеть LSTM, которая может быть от обучена с помощью восьми слоем энкодеров и декодеров. Мы можем разделить систему на три компонента: энкодер RNN, декодер RNN и модуль “внимания” (attention module). Энкодер работает над задачей преобразования входного предложения в векторное представление, декодер возвращает выходное представление, затем модуль внимания сообщает декодеру, на чем следует заострить внимание во время операции декодирования (здесь вступает идея использования всего контекста предложения).

Далее статья уделяет внимание проблемам, связанным с развертыванием и масштабированием данного сервиса. В ней обсуждаются такие темы, как вычислительные ресурсы, время задержки и массовое развертывание сервиса.